生成式AI模型实现MNIST数据增强
文档说明:
本文主要是作为我本身的结课的作业的一种提交形式。内容主要包括使用生成式AI模型实现MNIST数据增强。选用cGAN、VAE等生成式AI模型。在深度学习框架PyTorch上基于MNIST训练集优化所选生成式AI模型。基于定量性能指标:[分类准确率]对比无数据增强、有数据增强技术路线性能。并且对所选生成式AI模型分析其数据增强的效果差异并进行对比分析。
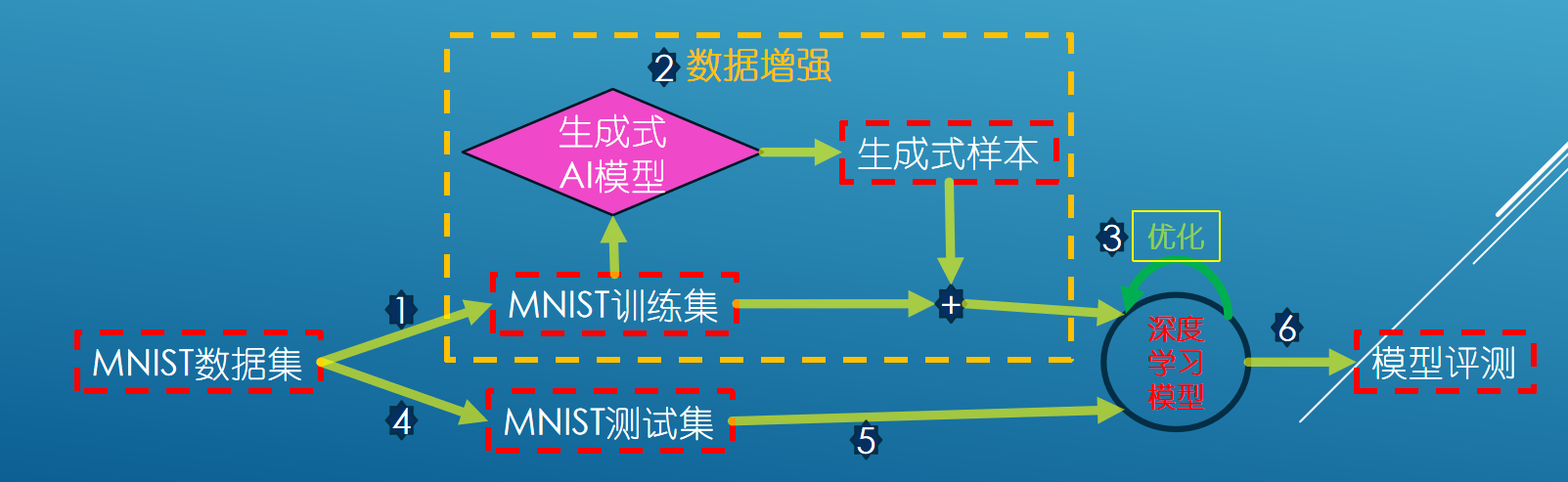
流程图如:
VAE数据增强实现部分:
VAE数据增强部分,我这里是分成了两个脚本文件来进行操作,其中一个文件是train_vae.py,这个文件主要是为了训练vae模型。然后还有一个文件,名字是generate_vae.py,该文件主要是利用训练好的vae模型对MNIST数据集进行数据增强,我这里是将MNIST的训练集中的每个样本图片都进行了重参数化(reparameterize)然后输入到Decoder中生成对应的数据样本,同时也是方便我获取生成样本的标签,这是因为VAE模型的Decoder是从潜在空间中生成的样本,本质上是无标签的,所以我要利用原样本的标签和其在潜在空间中的值,这会帮助我生成增强数据集。
VAE训练代码train_vae.py:
以下是我的homeWork/train_vae.py文件的说明:
该脚本在MNIST数据集上训练变分自编码器(VAE)。
依赖项:
torchtorch.nntorch.optimtorch.utils.datatorchvision.datasetstorchvision.transforms
VAE模型:
VAE模型由编码器和解码器组成。编码器将输入数据压缩到潜在空间表示,解码器从该表示中重构数据。
编码器:
- 输入:784维向量(展平的28x28图像)
- 输出:两个20维向量(均值和对数方差)
解码器:
- 输入:20维潜在向量
- 输出:784维向量(重构的图像)
重参数化技巧:
为了允许通过随机采样过程进行反向传播,使用重参数化技巧:$ z = \mu + \epsilon \cdot \sigma\ $其中$\epsilon$是从标准正态分布中采样。
损失函数:
VAE的损失函数由重构损失和KL散度组成:
- 重构损失:衡量重构图像与原始图像的匹配程度。
- KL散度:衡量潜在空间分布与标准正态分布的接近程度。
训练:
- 加载MNIST数据集。
- 初始化VAE模型和优化器。
- 训练模型若干个epoch,更新模型参数以最小化损失函数。
- 将训练好的模型保存到文件。
代码:
1 | import torch |
VAE生成代码generate_vae.py:
该脚本使用预训练的变分自编码器(VAE)生成MNIST数据集的样本,并将生成的样本保存为.ubyte文件格式。
依赖项:
torchtorch.nnnumpymatplotlib.pyplottorch.utils.datatorchvision.datasetstorchvision.transformstorchvision.utilsstruct
VAE模型:
VAE模型由编码器和解码器组成。编码器将输入数据压缩到潜在空间表示,解码器从该表示中重构数据。
编码器:
- 输入:784维向量(展平的28x28图像)
- 输出:两个20维向量(均值和对数方差)
解码器:
- 输入:20维潜在向量
- 输出:784维向量(重构的图像)
重参数化技巧:
为了允许通过随机采样过程进行反向传播,使用重参数化技巧:$z = \mu + \epsilon \cdot \sigma$ 其中$\epsilon$是从标准正态分布中采样。
保存增强数据集方法:
save_dataset(images_filepath, labels_filepath, dataset)函数将生成的图像和标签保存为.ubyte文件格式。
- 参数:
images_filepath:图像文件路径labels_filepath:标签文件路径dataset:包含图像和标签的列表
主要步骤:
- 定义VAE模型。
- 尝试加载预训练(如果有)的VAE模型权重。
- 加载MNIST数据集。
- 使用VAE生成样本。
- 将生成的样本保存为
VAE-Generated-images-idx3-ubyte文件和VAE-Generated-labels-idx1-ubyte。
代码:
1 | import torch |
CGAN数据增强实现部分:
CGAN训练代码train_gan.py:
依赖项:
torchtorchvision
CGAN模型:
生成器设计(Generator):
生成器模型用于生成与真实图像相似的图像。其结构如下:
嵌入层:
- label_emb:将类别标签嵌入到与噪声向量相同的维度中。
- 参数:num_classes(类别数),num_classes(嵌入向量维度)。
全连接层:
- fc:将噪声向量和嵌入标签连接起来,并通过全连接层进行处理。
- 全连接层参数:输入维度 input_size + num_classes,输出维度 num_feature。
卷积层:
- conv1_g:包含卷积层、批归一化层和ReLU激活函数。
- 卷积层参数:输入通道数 1,输出通道数 50,卷积核大小 3,填充 1。
- conv2_g:包含卷积层、批归一化层和ReLU激活函数。
- 卷积层参数:输入通道数 50,输出通道数 25,卷积核大小 3,填充 1。
- conv3_g:包含卷积层和Tanh激活函数。
- 卷积层参数:输入通道数 25,输出通道数 1,卷积核大小 2,步幅 2。
判别器设计(Discriminator):
判别器模型用于区分真实图像和生成图像。其结构如下:
嵌入层:
- label_emb:将类别标签嵌入到与图像大小相同的向量中。
- 参数:num_classes(类别数),28 * 28(嵌入向量维度)。
卷积层:
- conv1:包含卷积层、LeakyReLU激活函数和最大池化层。
- 卷积层参数:输入通道数 2,输出通道数 32,卷积核大小 5,填充 2。
- conv2:包含卷积层、LeakyReLU激活函数和最大池化层。
- 卷积层参数:输入通道数 32,输出通道数 64,卷积核大小 5,填充 2。
全连接层:
- fc:包含全连接层、LeakyReLU激活函数和Sigmoid激活函数。
- 全连接层参数:输入维度 64 * 7 * 7,输出维度 1024 和 1。
损失函数:
GAN模型的损失函数是二元交叉熵损失函数(Binary Cross-Entropy Loss),定义如下:
1 | criterion = nn.BCELoss() |
在训练过程中,判别器和生成器的损失分别计算如下:
判别器损失(
d_loss):1
2
3d_loss_real = criterion(real_out, real_label)
d_loss_fake = criterion(fake_out, fake_label)
d_loss = d_loss_real + d_loss_fake生成器损失(
g_loss):1
g_loss = criterion(output, real_label)
训练:
- 加载MNIST数据集。
- 初始化GAN模型和优化器。
- 训练模型若干个epoch,更新模型参数以最小化损失函数。
- 将训练好的模型保存到文件。
代码:
1 | import torch |
CGAN生成代码generator_GAN.py:
依赖项
该项目需要以下依赖项:
1 | torch |
CGAN模型
条件生成对抗网络 (CGAN) 是一种在训练过程中也利用标签的 GAN。生成器 - 给定标签和随机数组作为输入,该网络生成与对应相同标签的训练数据观察具有相同结构的数据。生成器用于生成与真实图像相似的图像,判别器用于区分真实图像和生成图像。在本文件中因为已经默认使用了MNIST数据集对模型进行过了训练,所以本文件中就没有用到辨别器(Discriminator),只用到了生成器。
生成器模型的结构如下:
嵌入层:
label_emb:将类别标签嵌入到与噪声向量相同的维度中。- 参数:
num_classes(类别数),num_classes(嵌入向量维度)。
全连接层:
fc:将噪声向量和嵌入标签连接起来,并通过全连接层进行处理。- 参数:输入维度
input_size + num_classes,输出维度num_feature。
卷积层:
conv1_g:包含卷积层、批归一化层和ReLU激活函数。- 参数:输入通道数
1,输出通道数50,卷积核大小3,填充1。
- 参数:输入通道数
conv2_g:包含卷积层、批归一化层和ReLU激活函数。- 参数:输入通道数
50,输出通道数25,卷积核大小3,填充1。
- 参数:输入通道数
conv3_g:包含卷积层和Tanh激活函数。- 参数:输入通道数
25,输出通道数1,卷积核大小2,步幅2。
- 参数:输入通道数
保存数据集的方法
该项目提供了一个方法来保存生成的数据集到 .ubyte 文件中:
1 | def save_dataset(images_filepath, labels_filepath, images, labels): |
主要步骤
导入必要的库:
- 导入
torch、torch.nn、numpy等库。
- 导入
定义生成器模型:
Generator类包含嵌入层、全连接层和卷积层,用于生成图像。
设置超参数:
- 定义噪声维度、类别数、生成样本数量和输出目录。
加载生成器模型:
- 初始化生成器模型,并加载预训练的模型权重。
生成数据集:
- 使用生成器模型生成指定数量的样本和标签。
保存生成的样本到
.ubyte文件:- 使用
save_dataset方法将生成的样本和标签保存到文件GAN-Generated-images-idx3-ubyte和GAN-Generated-labels-idx1-ubyte中。
- 使用
代码
1 | import torch |
三种数据集可视化对比展示:
原始MNIST数据集展示图:

VAE增强数据集展示图:

CGAN增强数据集展示图:

分别用三种数据集训练分类模型:
分类模型选择:LeNet5
我的这里的深度学习的分类模型选择的是LeNet5模型,当然LeNet5模型本身可以对图像的横向纵向进行特征提取就可以达到99%的正确识别率具体为:
LeNet5 模型
LeNet5 是一个经典的卷积神经网络(CNN)模型,主要用于图像分类任务。其结构如下:
卷积层 1 (
conv1):- 输入通道数:1
- 输出通道数:6
- 卷积核大小:5
卷积层 2 (
conv2):- 输入通道数:6
- 输出通道数:16
- 卷积核大小:5
全连接层 1 (
fc1):- 输入维度:16 * 4 * 4
- 输出维度:120
全连接层 2 (
fc2):- 输入维度:120
- 输出维度:84
全连接层 3 (
fc3):- 输入维度:84
- 输出维度:10
前向传播过程
- 输入图像通过第一个卷积层 (
conv1),然后经过 ReLU 激活函数。 - 经过最大池化层 (
max_pool2d)。 - 通过第二个卷积层 (
conv2),然后经过 ReLU 激活函数。 - 再次经过最大池化层 (
max_pool2d)。 - 将特征图展平为一维向量。
- 通过第一个全连接层 (
fc1),然后经过 ReLU 激活函数。 - 通过第二个全连接层 (
fc2),然后经过 ReLU 激活函数。 - 通过第三个全连接层 (
fc3),输出分类结果。
类代码如下:
1 | class LeNet5(nn.Module): |
损失函数和优化器:
设置损失函数:
criterion = nn.CrossEntropyLoss():使用交叉熵损失函数(Cross-Entropy Loss),这是一个常用的分类任务损失函数。
设置优化器:
optimizer = optim.Adam(leNet.parameters(), lr=learning_rate):使用Adam优化器,并设置学习率。Adam优化器是一种自适应学习率优化算法,适用于大多数深度学习模型。
1 | criterion = nn.CrossEntropyLoss() |
代码:
三种训练LeNet5的代码都一样只有数据集加载处有些改动,写的时候为了方便调试拆成了3个单独的文件,其中一个利用GAN训练增强数据集GAN_Train_LeNet_Combined.py的代码如下,(另外两个VAE和Original都类似,仅仅只有加载数据集过程中有些小区别):
1 | import torch |
效果对比
这里基于MNIST测试集对比三种训练集得到的模型做分类准确率评估评估效果如下:
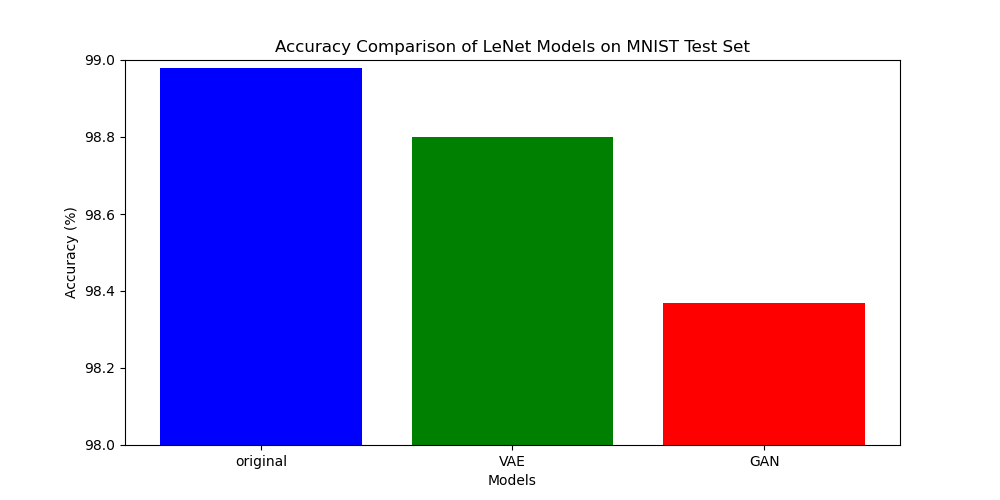
三种数据集分别训练LeNet5模型进行分类的成功率如下:
原始数据集:98.98%
利用VAE增强的数据集:98.80%
利用GAN增强的数据集:98.37%
结果分析
利用增强数据集训练的 LeNet 模型,分类效果略微下降了一些,但整体分类成功率仍能保持在 98% 以上。这可能是因为:
- VAE 和 CGAN 是基于训练集中的数据进行样本生成的,其生成的样本往往会使整个样本集的数据特征更加集中于某些特定方面。当生成的数据过于充分时,这种特性在训练 LeNet-5 时可能进一步削弱其泛化能力,从而导致过拟合,在测试集上表现为分类能力下降和性能减退。这一问题在 LeNet-5 这样的复杂多层卷积网络中尤为显著。
- 我认为,部分过拟合现象可能也与数据集本身过于简单有关。以 MNIST 数据集为例,其本身较为简单,而且训练集已经包含了 60,000 条数据,数量相当充足。在数据增强后,训练集的样本数量更是达到了 120,000 条。假设这些增强数据均为有效样本,那么对于像 LeNet-5 这样专注于分类任务的卷积神经网络来说,更容易出现过拟合现象。
- CGAN 的工作模式可能会加重过拟合现象。这是因为 GAN 模式中的 Discriminator 是基于训练集对 Generator 生成的数据进行辨别的,而这种对抗性机制会导致 Discriminator 和 Generator 在训练集上表现得过于“精准”,从而更容易出现过拟合问题。