AI网关架构设计
AI网关架构设计
引言
在人工智能技术快速演进的时代背景下,大型语言模型(LLMs)和 AI 智能体已成为各类应用的核心组件,引发 AI 相关 API 流量的指数级增长。随着企业将 AI 深度整合至业务流程,如何有效管理和优化 AI 驱动的交互正成为新的技术挑战。
以 DeepSeek 为代表的开源 LLM 技术兴起,使得企业不仅能够使用 OpenAI、Azure 等 SaaS 化 LLM 服务,更可在私有化环境中部署 LLM 模型,形成混合云架构。这一技术范式迁移带来了数据安全、多 LLM 适配管理、性能优化和可靠性保障等系列挑战,传统 API 网关向专业化 AI 网关 的演进势在必行。
详细设计与实施方案
需求分析
功能需求
| 需求类别 | 功能点描述 |
|---|---|
| 统一接入 | 提供单一、稳定、兼容 OpenAI 规范的 API 入口,屏蔽后端厂商差异。 |
| 认证授权 | 对接入的业务系统进行身份认证,并基于角色进行细粒度的模型访问授权。 |
| 密钥管理 | 集中、安全地管理所有下游厂商的 API Key,业务系统无需接触真实密钥。 |
| 智能路由 | 支持基于权重、延迟、成本、可用性的动态路由策略和故障自动切换。 |
| 流量控制 | 实现基于客户端、模型的 QPS 限流和基于 Token 用量的周期性配额管理。 |
| 可观测性 | 提供详细的调用日志、多维度监控指标(延迟、Token、费用)和可视化仪表盘。 |
| 提示词工程 | (高级)支持提示词模板、动态上下文注入和 RAG(检索增强生成)能力。 |
性能与安全指标
| 需求类别 | 指标要求 |
|---|---|
| 性能 | 高吞吐:初始目标 >1000 QPS,可水平扩展。低延迟:网关自身引入的延迟 P99 < 50ms。 |
| 安全性 | 密钥不落地、传输全程加密、严格的访问控制、防注入攻击。 |
| 可用性 | 关键组件无单点故障,支持集群化部署,目标可用性 > 99.95%。 |
| 可扩展性 | 采用插件化适配器模式,接入新厂商或新功能时对核心代码无侵入。 |
系统架构设计:微服务架构
系统架构图
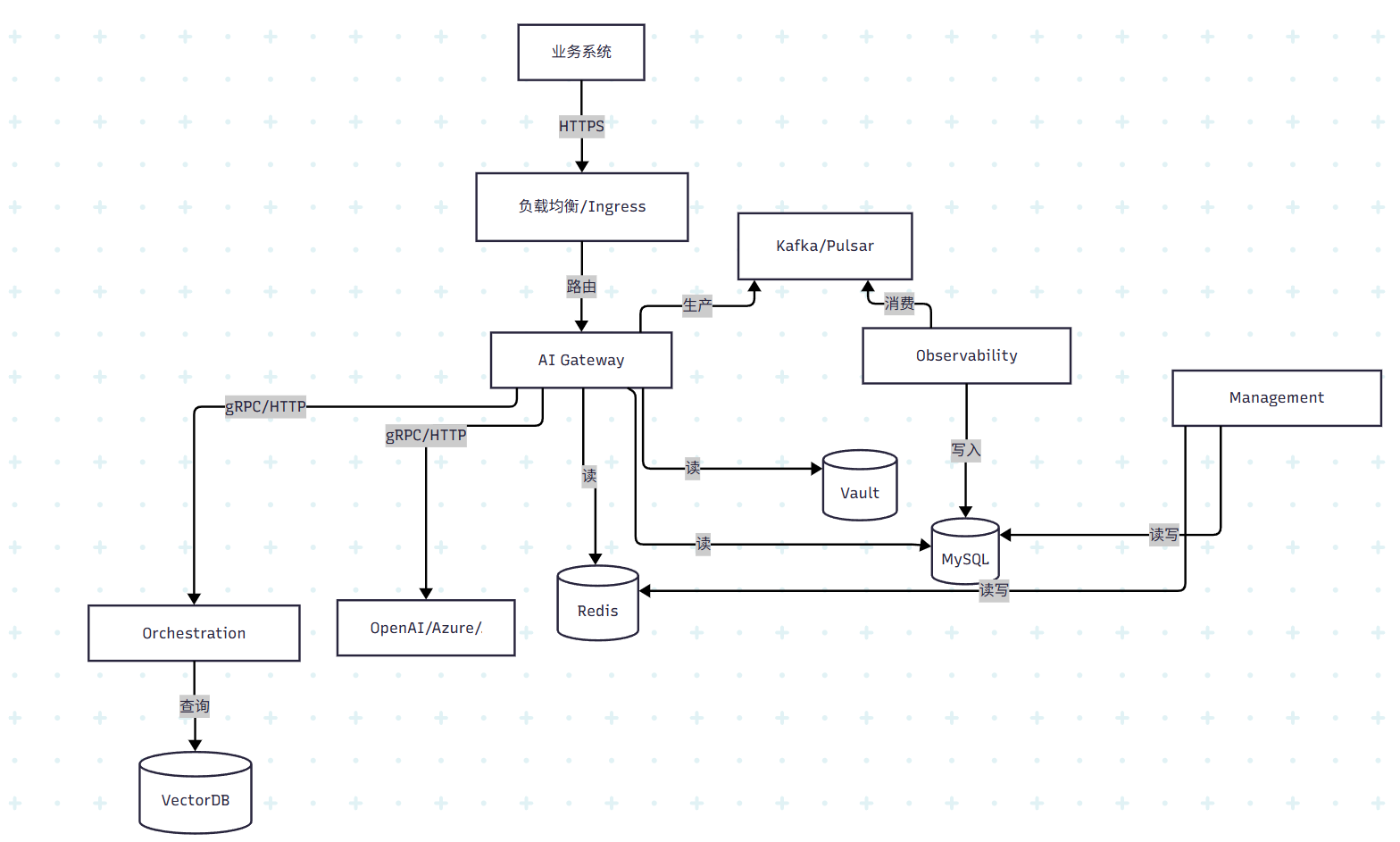
微服务职责划分
AI Gateway Core(网关核心)
- 职责:所有业务流量唯一入口,处理同步低延迟请求(认证、授权、限流、路由、协议适配、下游调用),支持高级功能(如 RAG)时同步调用 Orchestration Service。请求处理后将审计事件异步发布到消息中间件。
- 特性:无状态、轻量级、极致性能优化,属于数据平面。
Orchestration Service(编排服务)
- 职责:处理复杂提示词工程任务,实现 RAG 逻辑、提示词模板渲染、动态上下文注入等。
- 特性:可独立伸缩,适合计算密集型任务。
Observability Service(可观测性服务)
- 职责:异步消费审计事件,执行高延迟或批处理任务(如费用计算、日志写入、数据聚合),实现基于 Token 用量的配额检查与更新。
- 特性:日志与指标处理与核心请求路径解耦,保障性能。
Management Service(管理服务)
- 职责:提供 /api/admin/v1 管理接口,负责所有配置的 CRUD,包括客户端、路由、上游、权限等。配置变更时清除缓存或通知其他服务。
- 特性:控制平面,可用性不影响线上业务请求转发。
接口设计(API Specification)
对外 API
通用规范:
- Endpoint前缀:
/v1 - 消息认证:HTTP Header
Authorization: Bearer <gateway-api-key> - 数据格式:
application/json
- Endpoint前缀:
POST /v1/chat/completions
功能:与对话型大语言模型交互的核心入口,支持标准和流式(SSE)模式。
请求头:
Header Type 必填 说明 Authorization string 是 Bearer <gateway-api-key>Content-Type string 是 必须为 application/json X-Request-ID string 否 建议传入 UUID,用于全链路日志追踪 请求体:
字段 类型 必填 说明 model string 是 逻辑模型名称,如 “gpt-4-turbo” messages array 是 对话消息对象数组,不能为空 messages[].role string 是 角色,system/user/assistant messages[].content string 是 消息内容 stream boolean 否 是否流式返回,默认 false temperature number 否 0-2,控制输出随机性,默认 1 max_tokens integer 否 生成内容最大长度(token数) user string 否 终端用户唯一标识,建议传入 响应:
- 200 OK(标准/流式):请求成功
- 400 Bad Request:请求体格式错误
- 401 Unauthorized:认证失败
- 403 Forbidden:无权访问该模型
- 429 Too Many Requests:速率或配额超限
- 500 Internal Server Error:网关内部错误
- 503 Service Unavailable:所有下游服务均不可用
响应体 Schema(200 OK, 非流式):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28{
"id": "chatcmpl-gateway-abc123xyz",
"object": "chat.completion",
"created": 1677652288,
"model": "gpt-4-turbo",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "好的,这是一个关于..."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 30,
"completion_tokens": 1500,
"total_tokens": 1530
},
"debug_info": {
"request_id": "uuid-v4-goes-here",
"actual_upstream": "azure-gpt4-eastus-deployment-1",
"strategy_used": "latency-based",
"gateway_latency_ms": 45,
"upstream_latency_ms": 1850
}
}
POST /v1/embeddings
- 功能:文本转向量
- 请求体:
{ "model": "text-embedding-ada-002", "input": ["text1", "text2"] } - 响应体:
{ "object": "list", "data": [ { "object": "embedding", ... } ], "model": "...", "usage": { ... } }
管理 API
通用规范:
- Endpoint Prefix:
/api/admin/v1 - Authentication:独立 Admin 认证机制(如内部 JWT)
- Endpoint Prefix:
资源:Clients(客户端)
POST /clients:创建客户端GET /clients:查询客户端列表(支持分页)GET /clients/{clientId}:获取客户端详情PUT /clients/{clientId}:更新客户端信息DELETE /clients/{clientId}:逻辑删除客户端POST /clients/{clientId}/credentials:创建凭证DELETE /clients/{clientId}/credentials/{keyId}:吊销凭证
资源:Routes & Upstreams(路由与上游)
POST /routes:创建路由GET /routes:查询路由列表PUT /routes/{routeId}:更新路由DELETE /routes/{routeId}:删除路由POST /routes/{routeId}/upstreams:添加上游GET /routes/{routeId}/upstreams:获取某路由下所有上游GET /upstreams/health:实时返回所有上游健康检查状态PUT /upstreams/{upstreamId}:更新上游DELETE /upstreams/{upstreamId}:移除上游
安全设计
- 访问控制与身份认证:为每个业务系统生成独立 API Key,使用 bcrypt 哈希加盐存储。通过 RBAC 精确控制 Key 可访问的模型和功能。
- 密钥管理:所有下游厂商 API Key 由 Vault 加密存储和生命周期管理,服务通过 AppRole 动态获取,杜绝明文泄露。
- 传输安全:所有对外及服务间通信强制使用 TLS 1.2+ 加密。
- 微服务间安全(零信任网络):引入服务网格(如 Istio),自动提供双向 TLS(mTLS)和精细化服务间授权策略。
性能与高可用性设计
消息中间件解耦与削峰
- 选型:Apache Kafka 或 Pulsar。
- 作用:Gateway Core 快速发布审计事件到 Kafka,实现与 Observability Service 解耦,保障低延迟和最终一致性。
流量控制的实现
- 限流中间件:
- 在 CoreGW 中引入限流中间件,采用基于 Redis 的令牌桶算法实现。
- 每个客户端的 QPS 限流规则可动态配置,支持精细化控制。
- 配额管理:
- 配合
usage_quotas表,定期将配额数据同步到 Redis 缓存,减少数据库查询压力。 - 在请求处理时,实时检查缓存中的配额数据,确保 Token 用量不超限。
- 配合
可观测性与监控
- 定义关键性能指标(KPIs):
- 请求延迟:监控网关的 P50、P90、P99 延迟,确保性能符合预期。
- 成功率:统计 HTTP 状态码分布(如 2xx、4xx、5xx),监控请求成功率。
- 上游服务健康状态:定期检查上游服务的可用性和响应时间。
- 流量指标:监控每个客户端的 QPS 和 Token 用量,防止超限。
- 系统资源:监控 CPU、内存、磁盘 I/O 和网络带宽使用情况。
- 使用监控工具:
- Prometheus:采集系统和应用的监控指标。
- Grafana:可视化监控数据,创建实时仪表盘。
- Alertmanager:结合 Prometheus 设置告警规则,及时通知异常情况。
- 实现细节:
- 在 CoreGW 和 Observability Service 中集成 Prometheus Exporter,暴露监控指标。
- 配置 Grafana 仪表盘,展示关键性能指标(如延迟、成功率、流量)。
- 设置告警规则(如延迟超过阈值、成功率低于 99%),通过邮件或短信通知运维团队。
高并发场景下的性能优化
- 连接池与复用:
- 在 CoreGW 中使用连接池(如 gRPC 和 HTTP 的连接复用)。
- 配置全局
http.Client,优化http.Transport参数以支持高并发。 - 示例代码:
1
2
3
4
5
6transport := &http.Transport{
MaxIdleConns: 200,
MaxIdleConnsPerHost: 100,
IdleConnTimeout: 90 * time.Second,
}
client := &http.Client{Transport: transport}
- 多级缓存:
- 对于频繁访问的数据(如路由规则、配额),引入多级缓存:
- L1 内存缓存:使用高性能内存缓存(如
go-cache)。 - L2 分布式缓存:使用 Redis 存储共享数据,支持多实例访问。
- L1 内存缓存:使用高性能内存缓存(如
- 缓存策略:
- Cache-Aside 模式:先查询缓存,未命中时查询数据库并更新缓存。
- 配置变更时主动失效缓存,确保数据一致性。
- 对于频繁访问的数据(如路由规则、配额),引入多级缓存:
灾备与容灾设计
- 跨区域数据库主从同步:
- 配置 MySQL 的主从复制,支持跨区域同步,提升数据可用性。
- 使用异步复制模式,确保主库性能不受影响。
- 定期备份:
- 定期备份 Redis 和 MySQL 数据库,确保数据在灾难场景下可恢复。
- 备份策略:
- Redis:使用
RDB和AOF文件,定期上传到对象存储(如 AWS S3)。 - MySQL:使用
mysqldump或xtrabackup工具,生成全量和增量备份。
- Redis:使用
- 容灾演练:
- 定期进行容灾演练,验证备份数据的可用性和恢复流程的有效性。
- 多区域部署:
- 在多个区域部署关键服务(如 CoreGW 和 Redis),实现跨区域容灾。
- 使用负载均衡器(如 AWS ALB 或 GCP Load Balancer)实现流量切换。
内存与 GC 优化
- 高频大对象(如
[]byte buffer)用sync.Pool复用,降低 GC 压力。 - 尽量用
io.Reader/io.Writer流式处理,避免一次性读入大数据。
扩展性设计
功能扩展(插件化)
- Gateway Core 协议适配器插件化,支持新厂商仅需开发 Adapter 插件并部署,无需改动核心代码
系统扩展(差异化伸缩)
- 微服务架构允许各组件独立扩容
- API 请求量大时独立扩容 Gateway Core
- RAG 需求大时独立扩容 Orchestration Service
- 日志量大时增加 Observability Service 实例和 Kafka 分区
- 差异化伸缩高效应对复杂负载
- 如果大量业务使用RAG,可以独立扩容Orchestration Service的Pod数量。
- 如果日志量巨大,可以增加Observability Service的消费者实例和Kafka的分区数。
- 这种差异化伸缩能力是应对复杂多变负载的最高效方式。
数据库设计
AI 网关核心数据库采用 MySQL 8.0+,结合 Redis 做缓存。以下为 MySQL 版本的 ER 图、表结构(DDL)、关系与索引设计。
ER 图
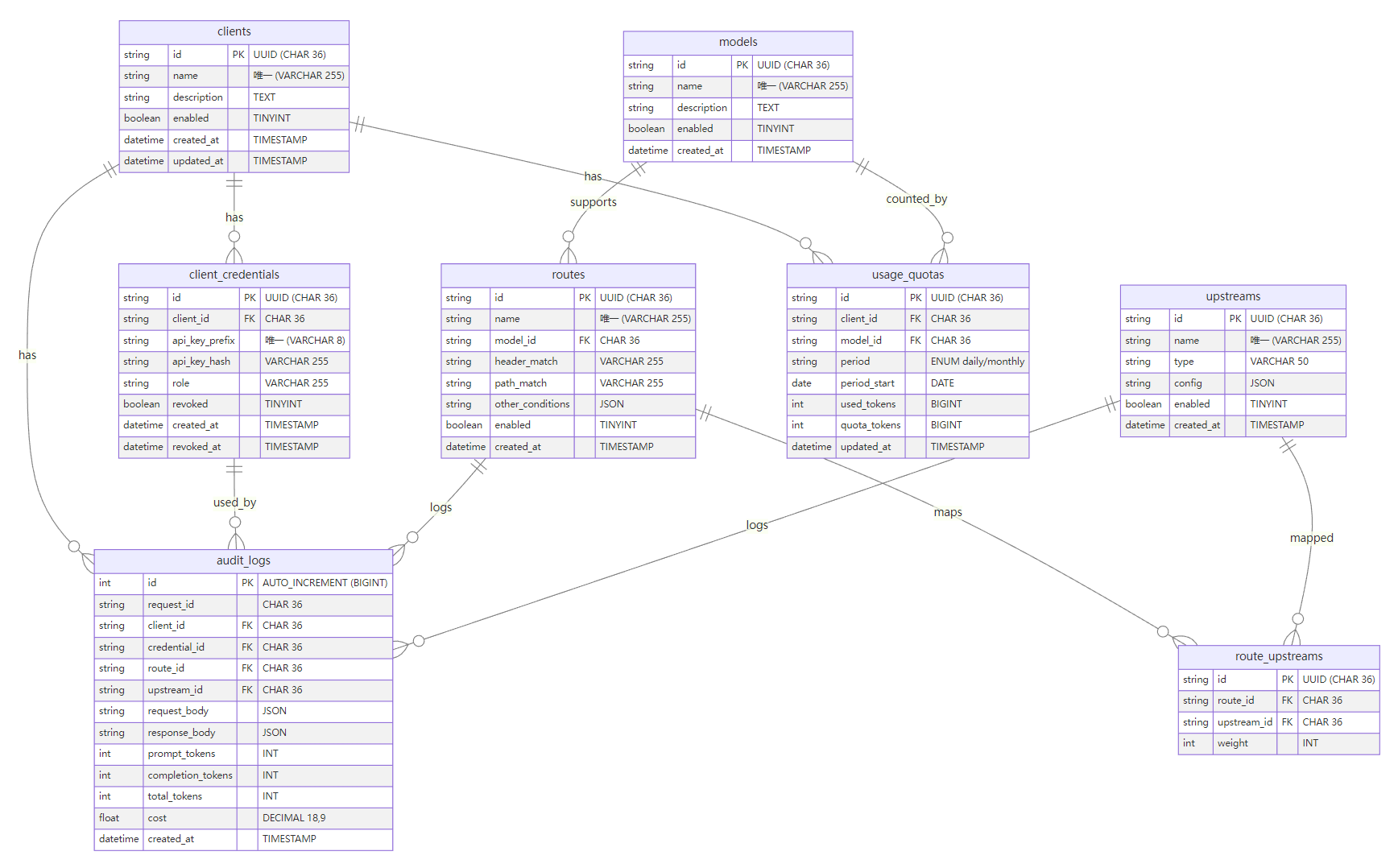
erDiagram
clients {
string id PK "UUID (CHAR 36)"
string name "唯一 (VARCHAR 255)"
string description "TEXT"
boolean enabled "TINYINT"
datetime created_at "TIMESTAMP"
datetime updated_at "TIMESTAMP"
}
client_credentials {
string id PK "UUID (CHAR 36)"
string client_id FK "CHAR 36"
string api_key_prefix "唯一 (VARCHAR 8)"
string api_key_hash "VARCHAR 255"
string role "VARCHAR 255"
boolean revoked "TINYINT"
datetime created_at "TIMESTAMP"
datetime revoked_at "TIMESTAMP"
}
models {
string id PK "UUID (CHAR 36)"
string name "唯一 (VARCHAR 255)"
string description "TEXT"
boolean enabled "TINYINT"
datetime created_at "TIMESTAMP"
}
routes {
string id PK "UUID (CHAR 36)"
string name "唯一 (VARCHAR 255)"
string model_id FK "CHAR 36"
string header_match "VARCHAR 255"
string path_match "VARCHAR 255"
string other_conditions "JSON"
boolean enabled "TINYINT"
datetime created_at "TIMESTAMP"
}
upstreams {
string id PK "UUID (CHAR 36)"
string name "唯一 (VARCHAR 255)"
string type "VARCHAR 50"
string config "JSON"
boolean enabled "TINYINT"
datetime created_at "TIMESTAMP"
}
route_upstreams {
string id PK "UUID (CHAR 36)"
string route_id FK "CHAR 36"
string upstream_id FK "CHAR 36"
int weight "INT"
}
audit_logs {
int id PK "AUTO_INCREMENT (BIGINT)"
string request_id "CHAR 36"
string client_id FK "CHAR 36"
string credential_id FK "CHAR 36"
string route_id FK "CHAR 36"
string upstream_id FK "CHAR 36"
string request_body "JSON"
string response_body "JSON"
int prompt_tokens "INT"
int completion_tokens "INT"
int total_tokens "INT"
float cost "DECIMAL 18,9"
datetime created_at "TIMESTAMP"
}
usage_quotas {
string id PK "UUID (CHAR 36)"
string client_id FK "CHAR 36"
string model_id FK "CHAR 36"
string period "ENUM daily/monthly"
date period_start "DATE"
int used_tokens "BIGINT"
int quota_tokens "BIGINT"
datetime updated_at "TIMESTAMP"
}
clients ||--o{ client_credentials : has
clients ||--o{ audit_logs : has
clients ||--o{ usage_quotas : has
client_credentials ||--o{ audit_logs : used_by
models ||--o{ routes : supports
models ||--o{ usage_quotas : counted_by
routes ||--o{ route_upstreams : maps
upstreams ||--o{ route_upstreams : mapped
routes ||--o{ audit_logs : logs
upstreams ||--o{ audit_logs : logs
详细表结构说明
以下为各表的设计与约束说明,包含设计思想和理由,具体 DDL 实现由数据库工程师负责。
- clients(接入方/业务系统)
- 用途:记录接入业务系统的基本信息及启用状态。
- 主要字段:
id:主键,UUID。name:客户端名称,需全局唯一。description:可选的文本描述。enabled:布尔值,标识是否启用。created_at/updated_at:记录创建和更新时间。
- 约束与设计要点:
name字段需唯一。- 推荐保留软删除策略(如需),由业务逻辑层控制。
- 设计思想:记录接入系统的基本信息,作为其他表的核心关联点。
- 设计理由:
- 通过
id唯一标识每个接入方,便于扩展和管理。 name唯一性确保接入方名称不冲突,方便查询和识别。enabled字段支持快速启停接入方,灵活控制接入权限。
- 通过
- client_credentials(API Key/凭证)
- 用途:管理每个客户端的访问凭证。
- 主要字段:
id:主键,UUID。client_id:外键,关联clients.id。api_key_prefix:API Key 前缀,唯一,用于快速定位凭证。api_key_hash:API Key 的哈希值(bcrypt),不存储明文。role:角色或权限域,与 RBAC 策略配合使用。revoked:布尔值,标识是否吊销。created_at/revoked_at:记录凭证的生命周期时间戳。
- 约束与设计要点:
api_key_prefix字段需唯一。- 建议开启级联删除(删除
client时清理其凭证),或由服务层保障一致性。
- 设计思想:为每个接入方生成独立的访问凭证,支持多 Key 和权限控制。
- 设计理由:
api_key_prefix提供快速定位凭证的能力,避免存储明文。role字段结合 RBAC 实现细粒度权限控制。- 支持吊销机制(
revoked),确保凭证的安全性和生命周期管理。
- models(逻辑模型)
- 用途:记录支持的逻辑模型(如 GPT-4、嵌入模型等)。
- 主要字段:
id:主键,UUID。name:模型名称,需唯一。description:可选的文本描述。enabled:布尔值,标识是否启用。created_at:记录创建时间。
- 约束与设计要点:
name字段需唯一。- 与
routes和usage_quotas表存在一对多关联。
- 设计思想:统一管理支持的逻辑模型,作为路由和配额的核心关联点。
- 设计理由:
name唯一性确保模型名称不冲突,便于路由规则的匹配。enabled字段支持快速启停模型,灵活控制模型的可用性。
- routes(路由规则)
- 用途:定义 API 请求的匹配规则及转发逻辑。
- 主要字段:
id:主键,UUID。name:路由名称,需唯一。model_id:外键,关联models.id。header_match:存储请求头匹配规则。path_match:存储路径匹配规则。other_conditions:存储其他复杂匹配条件(如 JSON 格式)。enabled:布尔值,标识是否启用。created_at:记录创建时间。
- 约束与设计要点:
name字段需唯一。- 高频查询字段(如
header_match和path_match)通过结构化存储并建立索引,提升查询效率。 - 对于复杂的匹配条件,仍可使用
other_conditions字段存储 JSON 数据。
- 设计思想:定义请求的匹配规则和转发逻辑,支持动态配置。
- 设计理由:
- 将高频查询字段(如
header_match和path_match)结构化存储,避免 JSON 查询性能瓶颈。 - 对复杂的匹配条件保留 JSON 存储的灵活性,兼顾性能与扩展性。
- 路由规则存储在数据库中,支持动态更新,无需重启服务。
- 将高频查询字段(如
- upstreams(下游服务商/模型实例)
- 用途:记录下游 LLM 服务实例及其类型。
- 主要字段:
id:主键,UUID。name:上游名称,需唯一。type:服务类型(如 OpenAI、Azure、私有模型等)。config:JSON 格式,存储实例配置(如 endpoint、region 等)。enabled:布尔值,标识是否启用。created_at:记录创建时间。
- 约束与设计要点:
name字段需唯一。- 敏感密钥不落地,
config中仅存储非敏感信息或密钥引用标识。
- 设计思想:统一管理下游服务实例,支持多厂商和多实例配置。
- 设计理由:
type字段区分不同厂商(如 OpenAI、Azure),便于运营和运维。config使用 JSON 存储实例配置,支持灵活扩展。enabled字段支持快速启停实例,便于故障隔离。
- route_upstreams(路由-上游映射)
- 用途:定义
routes与upstreams的多对多关系,并支持加权。 - 主要字段:
id:主键,UUID。route_id:外键,关联routes.id。upstream_id:外键,关联upstreams.id。weight:整数,表示权重(默认值为 100)。
- 约束与设计要点:
route_id+upstream_id需唯一。- 可按需开启对
route的级联删除。
- 设计思想:实现路由与上游服务的多对多关系,支持加权路由。
- 设计理由:
weight字段支持负载均衡和流量分配。- 通过
route_id和upstream_id唯一性约束,避免重复映射。
- audit_logs(调用审计日志)
- 用途:记录 API 调用的请求、响应、Token 用量及费用,支撑审计、计费与分析。
- 主要字段:
id:自增主键(适合高写入场景)。request_id:请求链路 ID(UUID)。client_id、credential_id、route_id、upstream_id:外键字段,记录调用上下文。request_body/response_body:JSON 格式,存储请求与响应内容。prompt_tokens、completion_tokens、total_tokens、cost:记录 Token 用量与费用。created_at:记录调用时间。
- 约束与设计要点:
- 高写入场景建议仅保留必要外键,或由服务层保障一致性。
- 按时间分区存储:基于
created_at字段按月分区,减少单表数据量,提升写入和查询性能。 - 冷热数据分离:将历史日志(如 6 个月前的数据)归档到冷存储(如对象存储或专用日志数据库),降低主数据库存储压力。
- 设计思想:记录每次 API 调用的详细信息,支持审计、计费和问题排查。
- 设计理由:
request_id提供全链路追踪能力。prompt_tokens和completion_tokens支持 Token 用量统计,便于计费。- 高写入场景下,使用自增主键优化性能,并支持分区或归档策略。
- usage_quotas(用量配额/统计)
- 用途:按
client×model×周期跟踪与限制用量。 - 主要字段:
id:主键,UUID。client_id、model_id:外键字段。period:统计周期(如 daily、monthly)。period_start:周期起始日期,与period共同界定统计周期。used_tokens、quota_tokens:记录已用与配额 Token 数(-1 表示无限制)。updated_at:记录最后更新时间。
- 约束与设计要点:
- 唯一键:
client_id+model_id+period+period_start。 - 支持幂等更新与原子累加。
- 可按周期归档或清理历史数据。
- 唯一键:
- 设计思想:按接入方、模型和周期跟踪用量,支持配额限制。
- 设计理由:
period和period_start定义统计周期,支持灵活的配额管理。quota_tokens支持无限制(-1)配置,满足不同业务需求。- 唯一键确保每个周期内的统计记录不重复,便于幂等更新。
关系说明
- 一对多
- clients → client_credentials / audit_logs / usage_quotas
- models → routes / usage_quotas
- routes → route_upstreams / audit_logs
- upstreams → route_upstreams / audit_logs
- 多对多
- routes ↔ upstreams 通过 route_upstreams 关联,并通过 weight 实现加权路由/故障切换。
- 审计闭环
- audit_logs 关联调用链关键实体,支持基于 request_id 的全链路追踪与基于时间/客户/凭证的统计查询。
索引设计与建议
- 唯一约束
- clients(name), models(name), routes(name), upstreams(name)
- client_credentials(api_key_prefix)
- route_upstreams(route_id, upstream_id)
- usage_quotas(client_id, model_id, period, period_start)
- 复合/普通索引
- client_credentials(client_id) 加速按客户管理凭证
- routes(model_id) 加速按模型检索路由
- routes(header_match, path_match) 提升高频路由规则查询性能
- upstreams(type) 支持运营/运维检索
- audit_logs:
- (request_id) 单次定位
- (client_id, credential_id) 客户/凭证统计
- (route_id, upstream_id) 路由与上游维度统计
- (created_at) 按时间窗口查询
- JSON 查询
- 对于
routes表中的other_conditions字段,建议仅在低频查询场景下使用 JSON 查询。 - usage_quotas(client_id, model_id, period, period_start)
- 对于
网关整体工作流程示例
对外来说,AI 网关对接业务系统,提供一个 统一的 OpenAI 兼容 API。业务系统的开发者只需要知道 网关的地址和 API Key,其余的复杂性(不同厂商 API 差异、密钥管理、路由策略)都被屏蔽掉了。
使用步骤
获取凭证
- 管理员在管理 API (
/api/admin/v1/clients) 里为业务系统创建一个 Client,并生成对应的 API Key。 - 业务系统只需要记住这个 Key。
- 管理员在管理 API (
调用 AI 网关的接口
假设调用对话模型:
1
2
3
4
5
6
7
8
9
10
11POST /v1/chat/completions
Authorization: Bearer <gateway-api-key>
Content-Type: application/json
{
"model": "gpt-4-turbo",
"messages": [
{"role": "user", "content": "帮我写一首七言律诗"}
],
"stream": true
}AI 网关返回和 OpenAI 格式一样的结果(支持标准响应和流式 SSE)。
查询用量与配额
业务方可以通过管理 API(未来扩展)查询自己的调用日志和 Token 使用情况:
1
GET /api/admin/v1/usage/quotas?clientId=xxx
避免超额调用。
对业务方而言,网关就是 一个统一的 LLM 服务入口,像用 OpenAI API 一样用,但实际上背后可能是 OpenAI、Azure、DeepSeek、甚至本地私有化模型。
AI 网关内部是怎么工作的
内部流程可以分成 核心请求处理路径 和 辅助管理/观测路径。
请求进入网关
- 业务请求先进入 AI Gateway Core(核心网关服务)。
- Gateway Core 执行以下步骤:
- 认证:校验 API Key(通过 Redis/DB 验证哈希)。
- 授权:检查这个 Key 是否有访问
gpt-4-turbo的权限(RBAC 控制)。 - 限流/配额:检查当前客户端是否超过 QPS/Token 用量限制。
路由与下游调用
- Gateway Core 根据配置的 路由策略,决定把请求发到哪个下游模型:
- 策略可能基于:延迟、权重、成本、可用性。
- 例如:优先发 Azure GPT-4,如果宕机就自动切到 OpenAI GPT-4。
- 请求发送到下游模型时,所需的 API Key 从 Vault 动态拉取(不是写死在代码里)。
高级功能(可选)
- 如果开启了 RAG 或提示词模板:
- Gateway Core 会调用 Orchestration Service,先执行检索增强、上下文拼接,再把增强后的 Prompt 交给下游模型。
响应返回
- Gateway Core 收到下游返回后,组装成 OpenAI 兼容格式,返回给业务系统。
- 同时,生成一条 审计事件(调用日志、Token 用量、费用信息),异步写入 Kafka。
后台异步处理
- Observability Service 消费 Kafka 事件:
- 记录审计日志(MySQL / 冷存储)。
- 更新
usage_quotas(Redis + DB)。 - 推送监控指标给 Prometheus(延迟、QPS、费用)。
- Management Service 负责:
- 提供管理 API(客户端、路由、上游配置)。
- 配置变更时通过缓存失效/事件通知广播给其他服务。
整体工作闭环
- 管理员 配置 Client、Route、Upstream。
- 业务系统 拿 API Key 调用
/v1/chat/completions。 - 网关 Core 验证身份 → 限流配额 → 智能路由 → 调用下游模型。
- 返回结果 给业务系统(OpenAI 风格)。
- 调用日志和用量 异步写入 Observability Service。
- 管理员/业务系统 可以通过管理 API 查看用量、配额、上游健康状态。
总结:
- 对业务系统:AI 网关就是一个统一的、安全的 API 入口。
- 对内部:AI 网关通过认证、限流、智能路由、密钥管理,把多个 LLM 服务封装成一个高可用、可观测、可扩展的服务层。